
AICVTG : Automatic Image Captioning
Published in North South University, 2023
The objective is to explore and implement image captioning using a combination of computer vision and natural language processing. The project aims to highlight the challenges in generating textual descriptions for images, emphasize the potential societal and economic benefits, propose a solution with image-based models (Vision Transformer) and language-based models (GPT-2), discuss the complexity compared to traditional computer vision tasks, detail the methodology using the MSCOCO dataset, and evaluate model performance through various image captioning metrics.
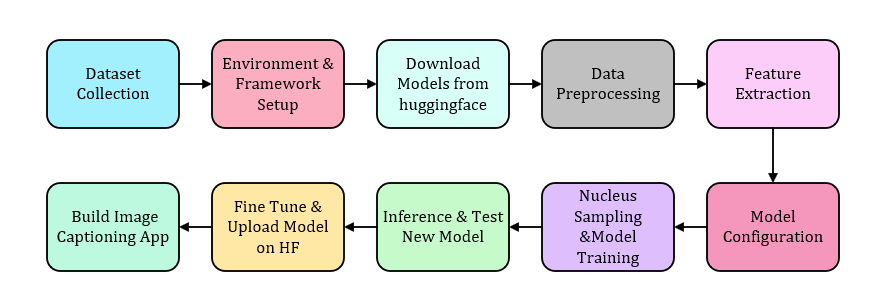
Figure 1: Block Diagram of Our Approach
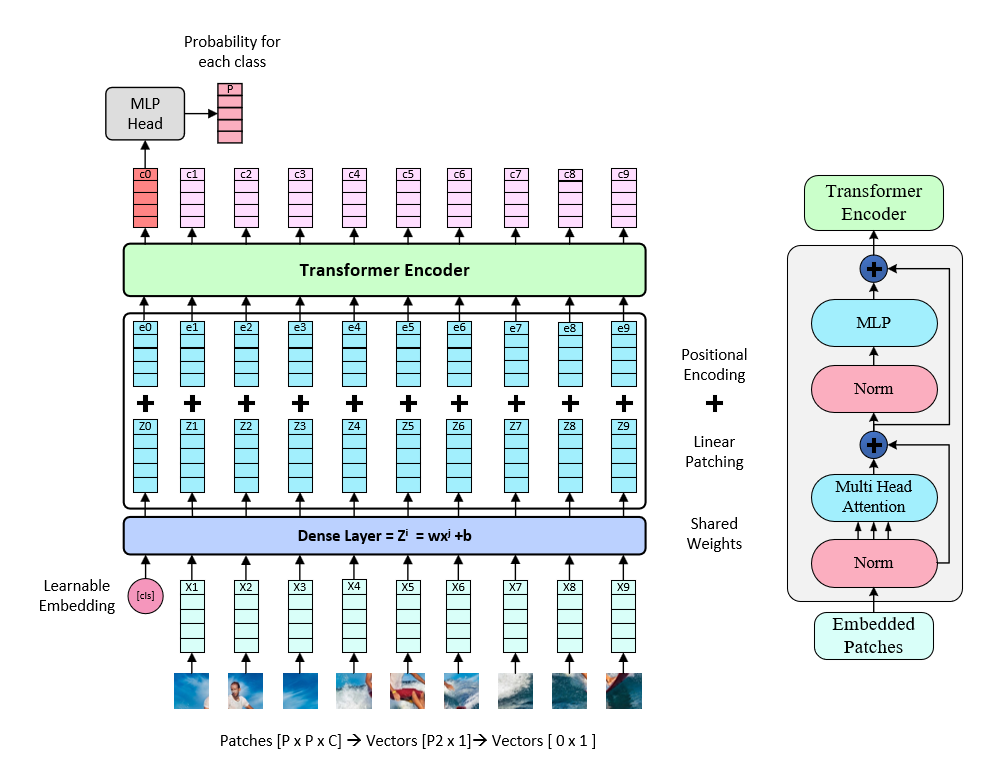
Figure 2. Vision Transformer Complete Network Architecture
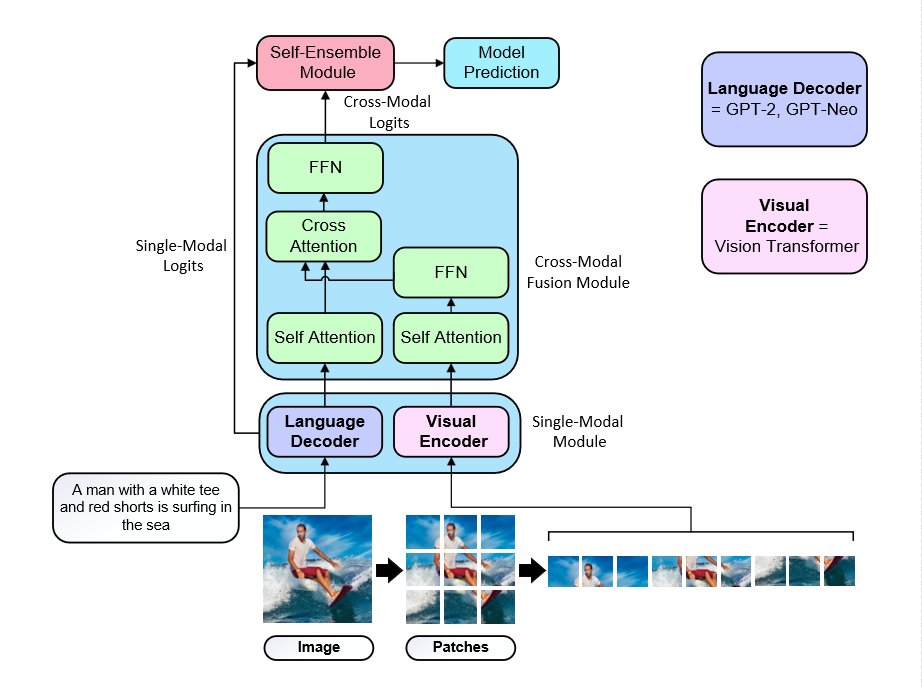
Figure 3: Our End-to-End ViT-GPT Framework
Project Demo
Supervisor: Prof. Shafin Rahman
Authors: S M Gazzali Arafat Nishan, Shafiul Bashar, Md. Imran Hossain